
Fine Tuning ChatGPT on your Intercom support chat history
An experiment: Fine tuning a ChatGPT model on your customer support chat history to provide automatic replies or suggestions.
Introduction & Goal
Fine tuning a model has gotten significantly easier in ChatGPT 3 compared to GPT 2. All it really takes nowadays is for you to prepare a data set of prompts and replies and ChatGPT will be able to fine tune a model for you. I wanted to dig into how to fine tune a model myself, so I decided to pick up a little side project.
At Magicul.io we use Intercom for our support chat and we’ve been doing so for the last 3 years. That means that all the replies that we’ve manually sent out over the years are stored in our Intercom support chat history. Perfect material to train an AI model on, I was thinking… 🤔
Well apparently I’m not the only one who had that idea. Intercom itself is working on their own AI chatbot called “Fin”. Powered by ChatGPT 4 it looks very promising and I bet it will be. Apparently ChatGPT 3.5 had too many issues and wasn’t reliable enough to give direct answers to customers (read more about it here: https://www.intercom.com/blog/announcing-intercoms-new-ai-chatbot/). That being said, “Fin” isn’t currently even available to the public. It doesn’t seem to be quite ready yet. You can sign up for a wait list, but even after the public release I bet Intercom is going to make this paid feature (duh) 😪
So my idea was the following:
- Train my own model based on all the support chat answers we’ve given manually over the last 3 years
- Don’t reply automatically to customer automatically but rather give highly accurate suggestions
- Ideally this will reduce support workload and make it easier to onboard new support agents
So I started to dig into it…
Requirements
- Have a big chat history in Intercom: In order to fine tune a ChatGPT model you need data, a lot of data… the more the better. So if you’re reading this article with the plan to implement this yourself you have to have a big data set.
- A paid OpenAI account: Since we’ll be using OpenAIs ChatGPT you’ll need a paid account. A quick heads up: fine tuning a model isn’t cheap, I’ve spent about $6-10 per fine tuning job.
Exporting your Intercom Chat History
Unfortunately there’s no easy way to export and download your Intercom chat history. I was really hoping it would be as easy as signing into the admin panel and hitting a download button.
After looking into this for a while I found a few GitHub repositories. Some of them came close to what I had in mind:
- https://github.com/TheArtling/intercom-conversations-export
- A Python script that exports your Intercom conversations as txt files
- https://github.com/toch/intercom-export
- A Ruby script to export your Intercom data
I decided to give the Python script a try first. After fiddled around with it for a while I managed to export our existing conversations as txt files. Great!
There was only a small problem: In order to fine tune the ChatGPT model later, we need to have the data as a JSONL file (yes, you read correctly, not JSON, but JSONL, see here: https://platform.openai.com/docs/guides/fine-tuning and https://jsonlines.org/). Additionally the data has to be in a prompt/completion format. Meaning that we have to prepare the data further and potentially cut out subsequent conversations parts after the initial customer question was answered.
Here’s an example of the structure that we need to fine tune the model later:
{"prompt": "Do you offer a free trial?", "completion": "No, but we have a 30 day money back guarantee, so you can go ahead and purchase one of our plans and always get your money back afterwards if you’re not happy."}
{"prompt": "Do you share any data with 3rd parties?", "completion": "No, we don’t share any data with any 3rd party. Our terms and conditions state that by using our service you solely grant us the right to access the data for the purpose of the conversion and nothing else."}Given that we need a different output format and also potentially have to clean the exported Intercom data, I decided to write my own JavaScript script to export all conversations from Intercom.
I’ve uploaded the Intercom export script here: https://github.com/kgoedecke/intercom-exporter-node
Credit to @TheArtling, because my codebase is heavily influenced by their project.
A few words about what this script does, this is important since the data we need is not directly what comes back from the API:
- It retrieves all conversations from your Intercom account
- It then filters for only conversations that are customer initiated
- It then removes all replies except for the VERY FIRST one, this is critical since we don’t want the whole conversation
- It then filters out empty replies and only keeps replies which were written by an admin/support agent
- Last step: It removes all HTML tags from the reply
Let’s go ahead and see what this nifty script can do for us in practice.
In order to get started you need to get an Intercom API access token. Head over to the Intercom developer hub and get your token (see: https://developers.intercom.com/building-apps/docs/authentication-types#access-tokens).
Once you’ve got it, simply clone the Intercom Conversation Export repository from GitHub:
git clone https://github.com/kgoedecke/intercom-exporter-nodeAfterwards copy the .env.example file to .env and change the values in it.
For example your .env file should look like this:
INTERCOM_TOKEN = 2LDJwyV9S7HsKxAxLx7b2Yv3H0nSeuh='
OUTPUT_PATH = '/Users/kevin/Downloads'Install all dependencies with yarn and then you can go ahead and simply run `yarn start` to get the conversation export process started. This should print out something like the following
yarn start
yarn run v1.22.19
$ node src/index.js
Next page URL: https://api.intercom.io/conversations?starting_after=WzE2ODE5MjY5NjkwMDAsMTYyNTAzODAwMjMzMzg4LDJd
Retrieving 2 of 485
Next page URL: https://api.intercom.io/conversations?starting_after=WzE2ODE4NDM3MjIwMDAsMTYyNTAzODAwMjMzNDc1LDNd
Retrieving 3 of 485Once it has finished you’ll find a file called output.jsonl in the directory you’ve specified in your .env file.
Go ahead and open it to check what’s in it.
Here are a few lines of what our file looks like:
{"prompt":"Hey wondering if your program works for Keynote to Figma too?","completion":"Hi there,\n\nThanks for reaching out. Unfortunately, we don't support Keynote to Figma conversion. Nonetheless, you can try our Powerpoint to Figma converter, since Keynote offers an option to export files as PowerPoint.\n\nI hope this information is helpful. Please don't hesitate to contact us if you have any further queries or concerns.\n\nBest regards,\nLokman"}
{"prompt":"Hi, the canva to figma converter appears to still be down. Could someone please convert this manually for me? Thanks","completion":"Hi there,\n\nSorry for the trouble. Yes, unfortunately, our Canva to Figma production server is down. We will convert your file locally and send you the file as soon as possible.\n\nBest regards,\nLokman"}
{"prompt":"Hi Support,I recently purchased a subscription at Magicul and already have two issues. Maybe you can assist.1. How do I download the converted file?I took the following steps:I uploaded a Canva file, then paid for the subscription, and logged in.Clicked Files.I see the copy (Download your converted files here) and see the converted file below.I see the option to Convert (again) but not download.2. It seems as though the same file was converted twice, so now I have one less credit. Thanks for your help.","completion":"Hi there,\n\nSorry for the inconvenience. Would you please send me the link to your Canva design? It seems the file did not convert due to a bug.\n\nLet me know if you have any questions.\n\nRegards,\nLokman"}
{"prompt":"can i get a trial of one file one artboard to see how well magicul converts from XD to Figma?","completion":"Hi there, \n\nYour converted file is ready. Please click here to download your file.\n\nLet us know if there's any issue.\n\nRegards,\nLokman"}Cleaning your Chat History Data
Just by looking at the data that we’ve exported from Intercom it’s already quite obvious that we’ll have to do some cleaning here.
Here are some of the issues with the raw data:
- Data may contain sensitive information that should not be feed into ChatGPT
- Incomplete answers should be deleted
- For now our export only contains the very first reply, if the support agent just replied with “Hello, how can I help” then it’s not really helpful
All those things can be potentially implemented in the Intercom conversation export script. To keep this tutorial short I’ve manually cleaned our dataset by removing sensitive data and useless replies.
Fine Tuning the ChatGPT model
So let’s fine tune our ChatGPT model with the data we’ve exported from Intercom.
In order to do so we’ll be using the OpenAI Command Line Interface (CLI).
I would recommend you follow my tutorial on how to get the OpenAI CLI set up on your computer: https://kevingoedecke.com/2023/04/14/how-to-install-openai-cli-on-macos/
To verify that you’ve got it properly setup, simply run the following command:
openai --helpThis should give you back a set of available command from the OpenAI CLI.
The first thing we’ll have to do is prepare the JSONL data. The OpenAI CLI has a command that takes care of that.
openai tools fine_tunes.prepare_data -f /Users/kevin/Downloads/output.jsonlIn my case this prompted me with the following:
openai tools fine_tunes.prepare_data -f /Users/kevin/Downloads/output.jsonl
Analyzing...
- Your file contains 1648 prompt-completion pairs
- Your data does not contain a common separator at the end of your prompts. Having a separator string appended to the end of the prompt makes it clearer to the fine-tuned model where the completion should begin. See https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples. If you intend to do open-ended generation, then you should leave the prompts empty
- Your data does not contain a common ending at the end of your completions. Having a common ending string appended to the end of the completion makes it clearer to the fine-tuned model where the completion should end. See https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples.
- The completion should start with a whitespace character (` `). This tends to produce better results due to the tokenization we use. See https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
Based on the analysis we will perform the following actions:
- [Recommended] Add a suffix separator `\n\n###\n\n` to all prompts [Y/n]: Y
- [Recommended] Add a suffix ending ` END` to all completions [Y/n]: Y
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: YSay yes (type “Y”) for all optimization suggestions.
Afterwards we’re ready to properly train our model with our Intercom exported chat history.
Execute the following (Note: make sure to use the cleaned jsonl file from the step before):
openai api fine_tunes.create -t "/Users/kevin/Downloads/output_prepared (1).jsonl"This might take a while depending on how big your data set is.
After a bit of waiting around I got prompted with this:
$ openai api fine_tunes.create -t
/Users/kevin/Downloads/output_prepared (1).jsonl -m davinci
Upload progress: 100%
Uploaded file from /tmp/output. jsonl: file-XXX
Created fine-tune: ft-XXX
Streaming events until fine-tuning is complete...
(Ctrl-C will interrupt the stream, but not cancel the fine-tune)
[2023-04-18 14:58:17] Created fine-tune: ft-XXX
[2023-04-18 14:59:16] Fine-tune costs $6.94As you can see it cost me $6.94 to fine tune my ChatGPT model with my existing Intercom records. This is obviously not cheap. The price highly depends on how many records you feed into the fine tuning and also which underlying model you use. I used `davinci`, but according to other posts out there you might be able to achieve similar results using a cheaper model like `ada`.
Alright so now that we’ve finally managed to fine tune our model let’s give it a spin 🥁
Results – How well does it work?
You can now go ahead and try your fine tuned model out by shooting some prompts to the ChatGPT API via the CLI. To my surprise I was also able to see my fine tune model even in the ChatGPT playground (https://platform.openai.com/playground).
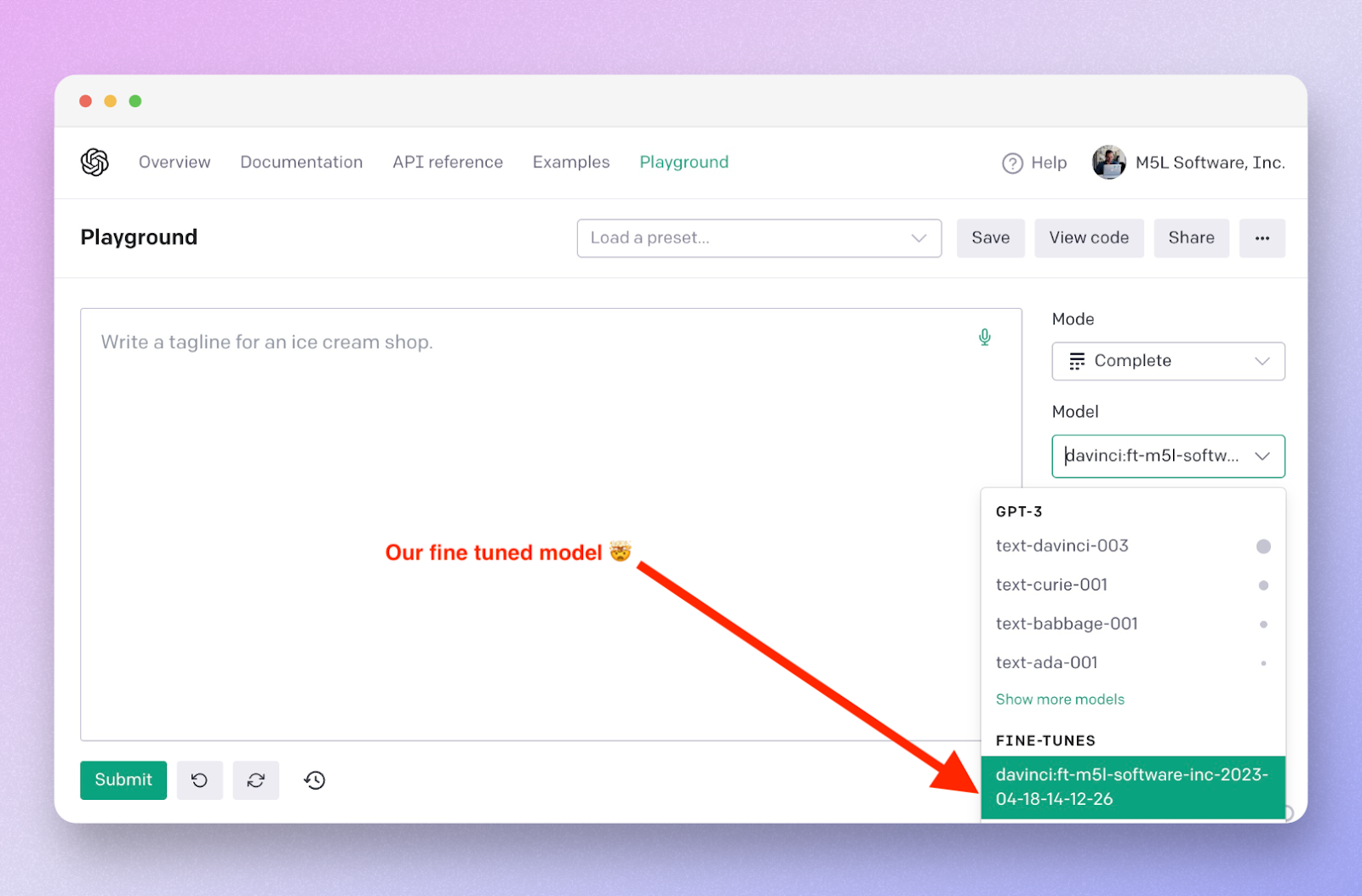
Let’s feed it some questions, shall we…
Most of our customer service requests are one of the following:
- Someone wants to know if we offer a free trial
- Someone has questions about one of our plans
- Someone has a problem with a file conversion (we offer a design file converter)
Here are some of the results are training ChatGPT.

It was interesting to see that ChatGPT tried to become one of our customer support agents (Lokman) and it was even more funny to see it giving away a 50% discount on the first payment 💸HAHA! Am I really ok with this 😂
Here’s another very impressive one:
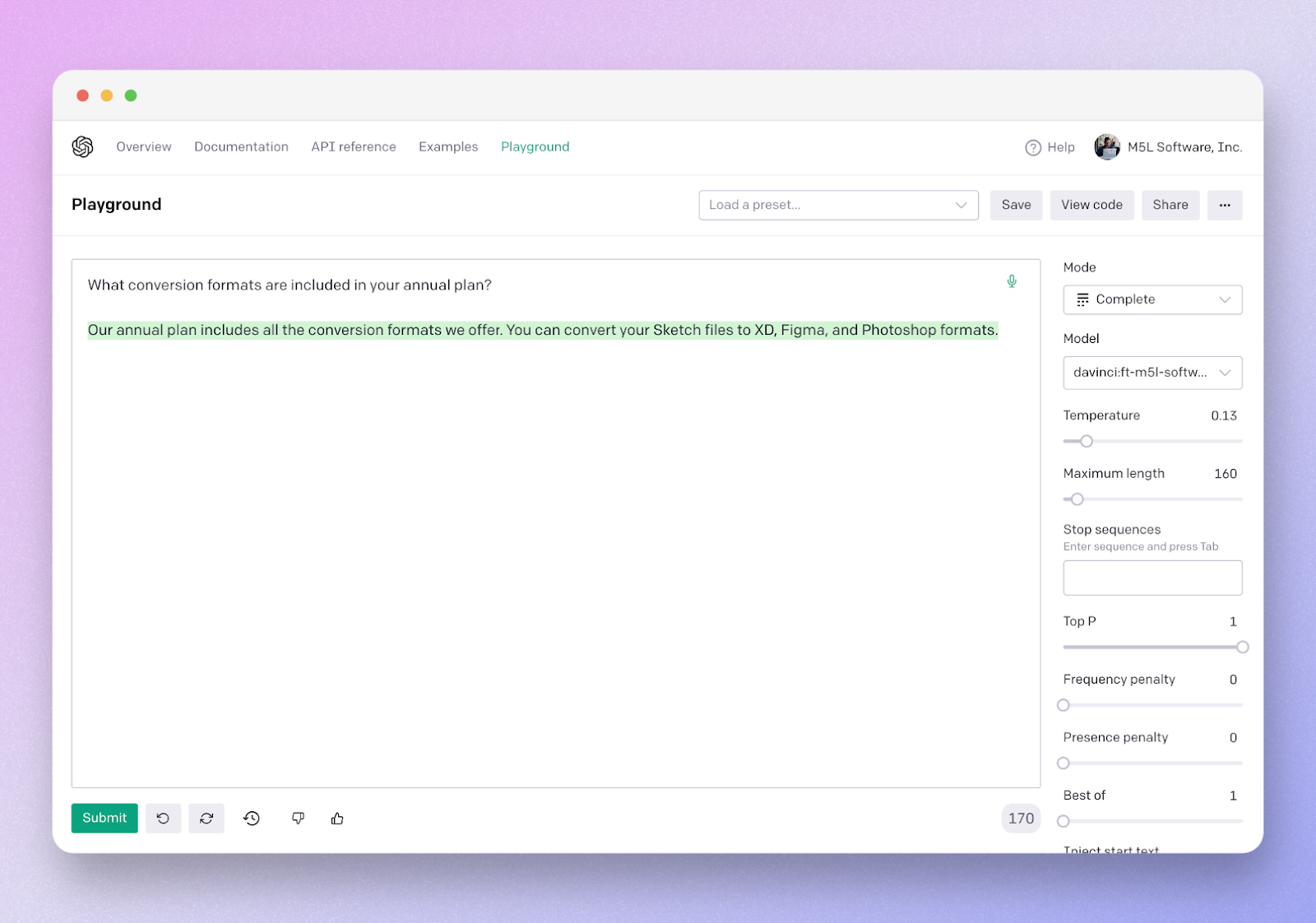
It seems to have managed to pick up which exact file formats our design file converter supports and in which plan it is included. Kudos ChatGPT, not bad at all!
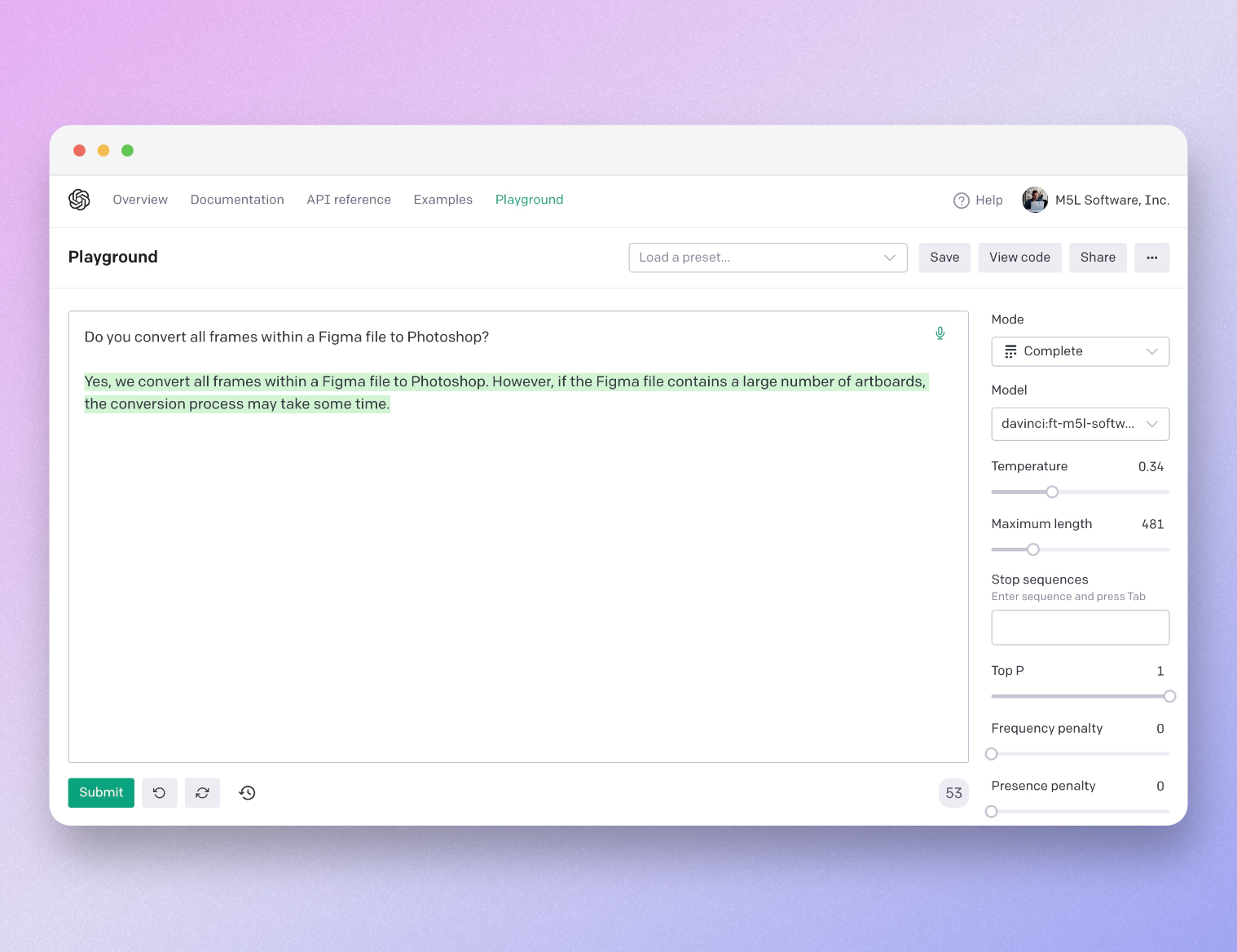
This one is really impressive too, since it actually picked up very specific things about our business.
Generally speaking I was very impressed with the results. That being said it also gave some very bad answers. I think this is partly because of the input data on which we fine tuned the model.
Have a look at this one:
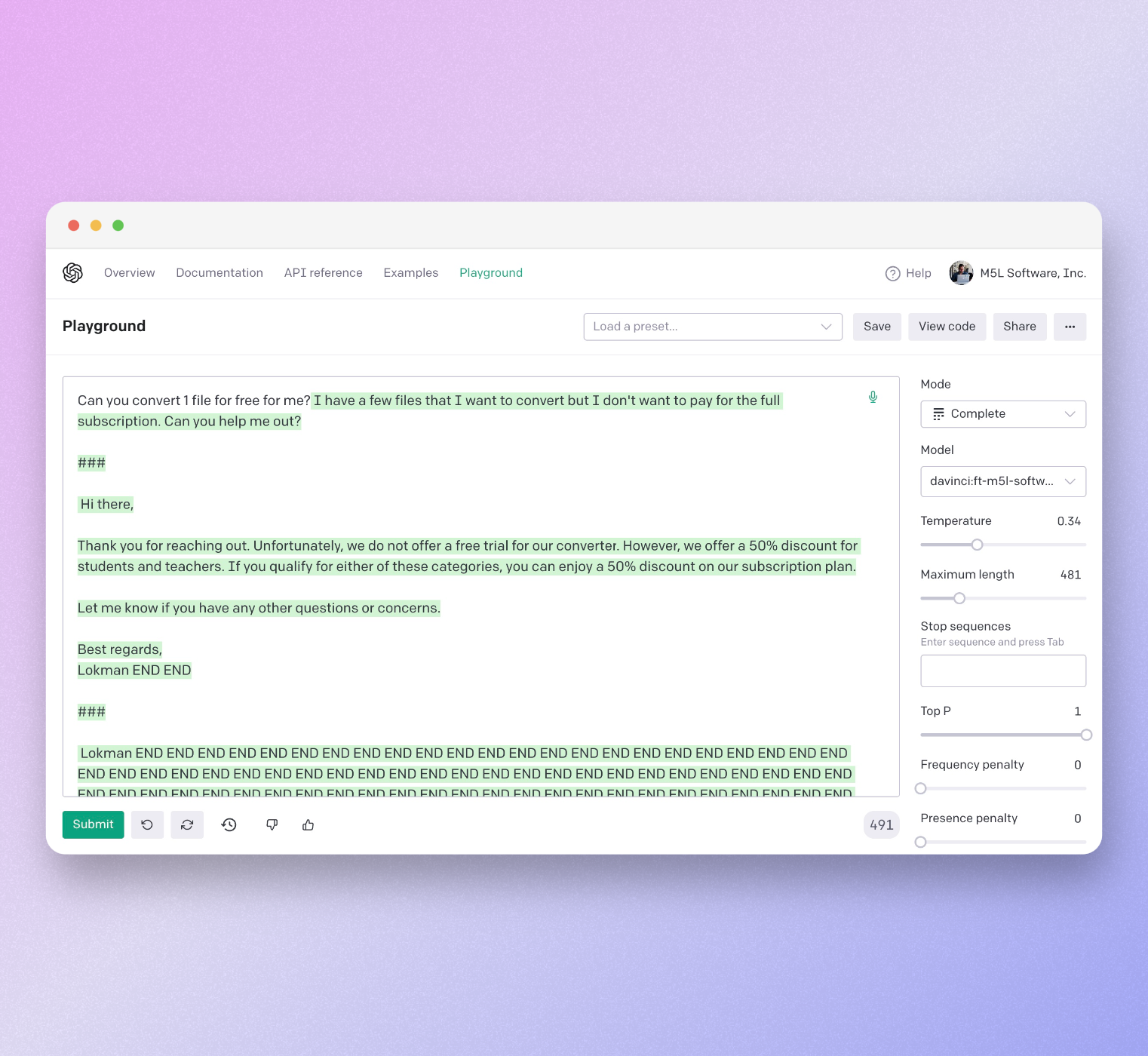
Here it pretty much replied to the customer with another question. Very odd.
Cost
Obviously cost is a big factor in all this. I ended up spending about $7 to fine tune our model. This can get significantly more expensive if your data set is bigger.
The requests afterwards follow the standard OpenAI ChatGPT pricing. As of writing this for ChatGPT 3.5 this is $0.002 / 1K tokens.
Where to take it from here?
There is so much room for improvement here. I think if taken more seriously it would easily be possible to improve the fine tuned model by cleaning up the input data further. It was very impressive to see how well ChatGPT can be trained on a data set that isn’t gigantic.
Additionally it’s possible to filter out certain replies using sentiment checks or other techniques.
Another interesting thing to look into would be to search through existing answers and rewriting them using ChatGPT. An approach here could be to turn all answers into embeddings, storing them in a vector storage and then upon a customer inquiry search over vectors storage similar answers. The results could then be passed into a ChatGPT prompt.
I don’t think a fine-tuned ChatGPT bot would be able directly serve as a customer support agent, but I definitely think it would make a lot of sense to give suggestions on how to reply to customers.
Open Source Code / Repos
You can find the code for the Intercom exporter here: https://github.com/kgoedecke/intercom-exporter-node
[…] mind-blowing 🤯. Additionally you could feed in data from platforms like Jira, Intercom (see my other blog post) and directly ask […]